Top 10 Online Roulette Casino for Real Money
Review of the Top 10 Online Roulette Casino for Real Money Casino Sites!
You can play real roulette at the best casino with a ball spinning wheel for desktop versions and mobile devices! Get your cashback bonus to play for real money!








The top 10 online roulette casino for real money are the places where you can start your real casino experience! Want to play online roulette real money casino now? All you must do is learn the simple rules of the roulette game simulator and try your fortune! This is a quite realistic task in today’s developed interactive gaming world. You just need a laptop, the Internet, and a bit of intuition! No! You don’t have to dive into complicated math formulas. You can try the top roulette games available both for free and real money, play American roulette, or try a classic roulette strategy at our recommended online casinos.
Looking for a variety to play online roulette for real money? Our top picks feature roulette games that go beyond the conventional, offering the option to bet on five numbers and a black number for a unique spin on the classic game. It’s worth checking these recommended sites out to add an extra layer of excitement to your gameplay! Additionally, players can deposit funds seamlessly, thanks to user-friendly interfaces that prioritize convenience and efficiency.
To enhance the gaming experience, these online casinos present enticing opportunities through their VIP programs, ensuring that players feel valued and appreciated. The casino offers various promotional incentives, including weekly prizes, enticing both new and existing players to partake in the thrill of online roulette. Additionally, players can deposit funds seamlessly, thanks to user-friendly interfaces that prioritize convenience and efficiency.
For those seeking an added layer of excitement and strategic depth, some recommended online platforms incorporate the en prison rule. This rule allows players to recover their bets or leave them for the next spin, introducing an intriguing element of risk management to the game. By exploring these recommended sites, players not only enjoy the thrill of online roulette but also gain access to exclusive features, promotions, and innovative rules that elevate their gaming experience to new heights.

What is an Online Roulette Real Money Casino? Roulette Background
Real online roulette in the digital world is like the classic roulette games but played on the Internet. From your computer or phone, you get to experience the excitement and thrill first-hand. After each spin, a random number generator determines where the ball lands to keep things fair.
Online roulette is an engaging and legal virtual rendition of the classic casino game. It involves placing bets on various outcomes as a digital ball spins on the online roulette tables. Online roulette real money casino players have the option to explore different versions, such as multi ball roulette, which adds an exciting twist to the traditional game.
Many platforms allow users to play roulette for free, providing a risk-free environment for honing skills or simply enjoying the game without financial stakes. To enhance the overall gambling experience, it’s essential to find a good online roulette table, ensuring a fair and enjoyable gaming session within the legal parameters of online gambling.

Diving back to the Roulette game history to understand the game
With its intriguing history, roulette dates back as far as 17th century France. A French mathematician and inventor, Blaise Pascal accidentally invented the spinning wheel while playing with a perpetual motion machine. In 1842, brothers François and Louis Blanc introduced the world’s first recognizable wheel; with just a single zero it increased in popularity rapidly.
European online casino games adopted roulette, and by the 19th century, it had crossed to America where it was given a home in American gaming houses. However, the American version added to the wheel two double zeros. This led to two different versions of roulette: to play European roulette wheel and the American roulette wheel.
In the 20th century, with the development of Internet technology, a good selection of the famous roulette games in casinos also moved online. This transformation enabled players to enjoy this roulette live online game conveniently from home. Genuine online roulette arrived in the 21st century. This allowed players to place bets, spin the wheel, and feel themselves being carried along on this tide of adventure through computer networks, making roulette an international phenomenon.
How does real money roulette differ from a roulette free version?

The main difference between real online roulette and the free roulette wheel is that the former uses real money for placing bets, while the latter uses fake in-game currency. This means that real money roulette involves financial risk and reward, while roulette free version is purely for fun and practice. The key aspects where they differ:
- Real online roulette is more exciting and thrilling than a free roulette wheel, as you can win or lose real money.
- Roulette online real money wheel offers a variety of bonuses and promotions, such as welcome bonuses, loyalty programs, and cashback offers, that the free option does not have.
- Online roulette with real money has more options and features, such as live dealer roulette, multi-wheel roulette, and mini roulette, that the free version may not offer.
- Free roulette wheel allows you to familiarize yourself with the rules and bets of roulette, without risking any money. You can also test different strategies and experiment with different bets.
- Roulette free wheel lets you play for as long as you want, without any limits or restrictions. You can also switch between different roulette games and variants easily.
You can find more information about the roulette wheel and table or refer to the guide on how to win roulette for free or real money. You can also discover progressive jackpot games, poker games, or other benefits on the top roulette casinos found on our platform. We recommend and describe only fully licensed casinos with ssl encryption methods so that you can find a real money roulette site where the majority of online casino players take a fortune!
How to Understand Online Roulette Wheel: Simple Rules of Roulette Simulator
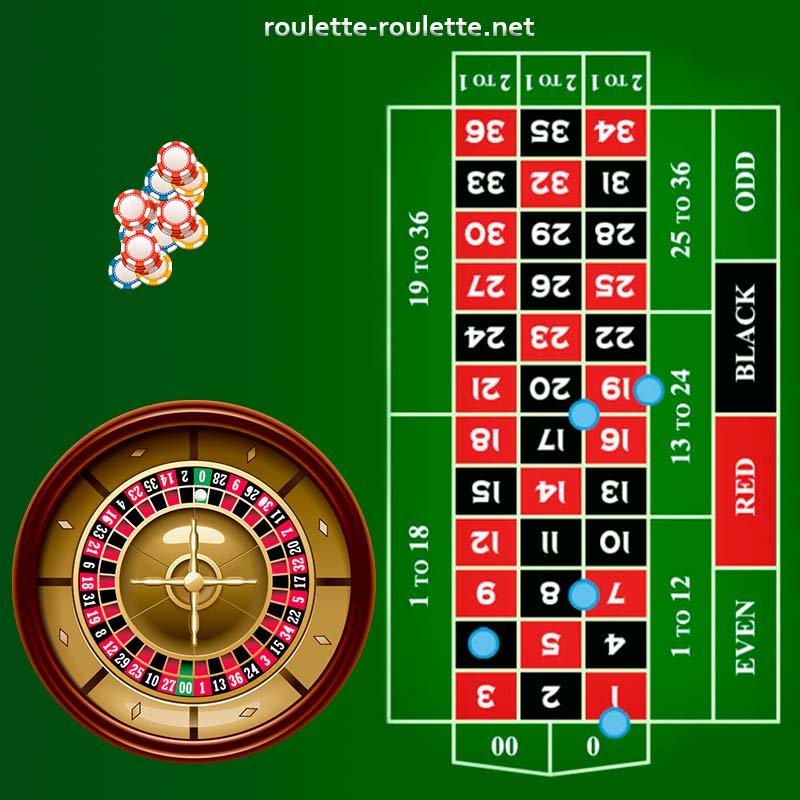
A roulette wheel is an item used in the game, which is a chance-based roulette casinos game. It has special pockets that usually go from 0 to 36. They are often red or black in color. The wheel turns one way, and a ball moves in the other direction. The place where the ball lands in a hole decides who wins.
A roulette online simulator is like a fun thing on your computer or phone where you can play for free. You can choose different kinds such as to play European roulette, American or French ball game, and place bets on a made-up roulette table. The simulator uses a random number maker, same as in real roulette game.
We’d like to focus your attention on basic roulette gambling online rules. Exploring the diverse landscape of online roulette becomes an enriching experience when engaging with top roulette casinos. The basic rules for online roulette are much like those in a regular casino:
- Place your bets, spin the roulette wheel, and see where it goes all this going on over the Internet you feel like you’re in a real money casino. It is the favorite of those who like traditional roulette and would play it easily anywhere.
- Guess where the ball will stop and bet your money in that place
- Place a wager on just one number, a bunch of numbers, or other classifications like colors
- Payments are based on how clear your bet is and the kind of roulette you play. For example, a one-number bet gives 35 for each win while betting on red or black only wins you an extra point
- Get and use casino bonuses when available. It increases your chances to win real money quickly
The big difference between playing roulette and in real life is that it’s faster and easier to do online. You can play whenever and wherever you like. It is essential to prioritize licensed online roulette casino sites to ensure the legality and security of your gameplay. The best roulette site bonuses amplify the excitement, offering generous welcome bonuses that enhance your initial gaming ventures.
Top 10 Online Roulette Casino for Real Money to Try the Game
What is the best online roulette site? When exploring the realm of online roulette, it’s crucial to navigate to the top roulette sites to ensure a seamless and legal gaming experience. The best roulette sites often offer a variety of options, including the fast-paced thrill of speed roulette.
Additionally, players can benefit from enticing bonuses specific to each platform. These bonuses not only add value to your gameplay but also distinguish the best roulette site from other online roulette sites. Always choose reputable platforms where online roulette is legal, ensuring a secure and enjoyable environment for your gaming endeavors. Our team made a comprehensive study and found best roulette casinos where you can play roulette games online:
✅ MyBookie: An online casino real money platform which is a common type of platform offering a good selection of games and promotions similar to those found in physical casinos. This online roulette site accepts a range of payment methods including cryptocurrencies, and is licensed under Curacao.
✅ Windetta: In 2023, a new real money casino online platform was launched with an online platform featuring a mafia-themed environment and an impressive collection of more than 5000 games from top-notch software providers. A Curacao license provides a welcome package, cashback rewards, and VIP program.
✅Nine: A real money online casino that was created recently in 2021 and provides a vast collection of more than 5,000 games developed by top-notch providers, featuring live casino and progressive jackpot games available. Being in possession of a Curacao license, it extends a warm welcome to new members with a three-part bonus cash package.
✅ Zodiac Bet Casino: This online roulette site and sports betting platform provides a range of games and sports, as well as a license from Curacao. The platform belongs to the best online roulette sites and offers more than 200 games that include slot machines, table games, and live online roulette platforms for real money, and supports multiple currencies and available payment options including cryptocurrencies.
✅Powerplay: A leading online Canadian casino and straight up bet platform that belongs to the quality online casinos and provides over 250 different games, which include slot machines, table games, and live casino. A welcome deposit match bonus of C$1000 is given to new online players when they obtain a Kahnawake license.
✅ Jokabet: In 2023, a new real money casino and sports betting platform was launched that does not belong to Gamstop and provides more than 5000 games from over 60 providers. These games include various types such as slots, table games, and live casino options. It attracts new gamblers by providing an introduction bonus of 255% up to £450 and an additional 250 free spins, given that the player friendly holds a Curacao license.
✅Richard Casino: An establishment that offers online gambling services with a substantial $5,000 welcome bonus, a wide variety of more than 200 games, and banking options that support both FIAT and cryptocurrencies. Featuring a distinctive lion theme, it operates under a Panama license.
✅ Joo Casino: A real money casino online platform that provides a diverse range of games over 300, including slot machines, table games, and live casino experiences. Under the license of Curacao, it supports multiple currencies and cryptocurrencies. A four-part welcome bonus and a VIP program are available at the casino.
✅ JackpotCity: One of the famous online Canadian casinos founded in 1998 that features over 300 assorted games, comprising of slot machines, table games, and live casino alternatives. The platform offers a welcome bonus of C$1600 for new online players and has a loyalty program with daily spins for a chance to win a million.
✅ Wild Casino: An online gambling site that is licensed in Curacao and has a wide range of over 350 games, such as slots, table games, and video poker. The platform allows various modes of payment, including digital currencies, and provides a substantial reward of $5,000 to new members.
When comparing online roulette casinos to their brick and mortar counterparts, the advantages become evident. Online platforms, such as BetRivers Casino, not only offer the classic charm of roulette but also provide a vast array of other games, catering to diverse gaming preferences beyond the roulette wheel commonly found in a traditional land-based casino.
Choosing the best online casino among the top 10 roulette casino for real money
The best roulette online casinos where you can play real money games are presented by our team in this table. Make a choice with the best deposit bonuses on proposed online casino platforms. You can find there also other table games to play. These platforms are checker and reliable with their friendly, careful customer support services, and a big variety of real money roulette games, progressive jackpots, and many other casino games.
| Casino 🎰 | Roulette Type | Min Deposit | Free Spins | Wagering Req | RTP% | Max Withdrawal | Popularity |
| MyBookie | European and American roulette, Zoom | $10 | N/A | 40x | 96% | $2,000 per week | ⭐️ ⭐️ ⭐️ ⭐️ |
| Windetta | European version and American roulette, Zoom | $20 | 150 + 75 | 35x | 97% | $15,000 per month | ⭐️ ⭐️ ⭐️ |
| Nine Casino | American, European roulette, French, Live | $20 | 250 | 50x | 96% | $15,000 per month | ⭐️ ⭐️ ⭐️ |
| Zodiac Bet | American, European roulette, French, Live | $10 | N/A | 40x | 95% | $50,000 per month | ⭐️ ⭐️ ⭐️ ⭐️ |
| Powerplay | American, European roulette, Live casino games | $10 | N/A | 35x | 96% | $100,000 per month | ⭐️ ⭐️ ⭐️ ⭐️ ⭐️ |
| Jokabet | American, European, French, Live roulette casino games | $10 | 250 | 40x | 96% | $15,000 per month | ⭐️ ⭐️ ⭐️ |
| Richard | American, European, Zoom | $10 | N/A | 40x | 96% | $2,000 per week | ⭐️ ⭐️ ⭐️ ⭐️ |
| Joo | American, European, French, Live casino games | $20 | 150 | 50x | 96% | $2,500 per week | ⭐️ ⭐️ ⭐️ ⭐️ |
| JackpotCity | American, European, French, Live roulette casino games | $10 | N/A | 70x | 97% | $10,000 per day | ⭐️ ⭐️ ⭐️ ⭐️ ⭐️ |
| Wild | American, European roulette, Zoom | $20 | N/A | 30x | 97% | $100,000 per month | ⭐️ ⭐️ ⭐️ ⭐️ |
Canadian casinos online players enjoy substantial advantages. Some are good at giving different types of roulette games and roulette variations, while others shine with lots of free spins. Things like very high payout rates and higher cash-out limits make them different from each other.
These Canadian online casinos have things in common, but they also show differences. These differences are about types of roulette games, how much you need to put in at least, if there’s roulette for free available or not. It also talks about what the RTP rates are like fully and limits on payouts overall popularity too. Now, it’s clear what is the best roulette site to play.
Online Roulette Variants of the Top Ball Wheel Gambling Platforms



Roulette is a popular casino game that has several variations, each with its own rules, features, and odds. Which roulette game in casino to play? We have performed this roulette online casino review and outlined the three most popular types of the best online roulette games:
- European Online Roulette: This is the first and most liked form of roulette. It has a circle with 37 areas, numbered from zero to thirty-six. The zero is green, but the others are red or black. The casino has a small edge with a 2.7% house lead. Regular roulette has better chances than other kinds but might not be as fun.
- American Roulette: A change to the old roulette game, with an extra spot – double zero- which brings total pockets up to 38. The odds go up to 5.26%. Playing online roulette in American style is more fun but gives players a lower chance of winning.
- French Roulette: Another type of old popular roulette variants with rules that are good for players like En Prison and La Partage. These rules apply to outside bets where the odds are even. In Prison, players can get back half of their bet or use it for the next turn if zero comes up. La Partage lets you quickly get back half of your bet. French roulette has the best chances with only a 1.35% house edge for outside bets that pay even money, but it might be harder to find.
- Double Ball Roulette: A new change using two balls instead of one, often in a European wheel with different payouts. Roulette with two balls gives more chances to bet and bigger rewards, but it can be harder than other versions.
As we can see, it’s possible to choose between four main roulette variations. Live roulette games are available on various platforms, however, a licensed casino site with a generous welcome bonus in addition is always preferable. Compare all types of real roulette variants played in these best roulette casino platforms for real money and not only:
| Roulette Type | Casino Type | Main Feature | Pros 😊 | Cons 🙁 |
| European | Online and land type | Single zero | Better odds than other variants | Less exciting than other variants |
| American | Online and land-type | Double zero | More thrilling and challenging than other variants | Higher house edge than other variants |
| French | Online and land-type | En Prison and La Partage rules | Online and land-type | Harder to find and play than other variants |
| Double Ball | Online and land-type | Two balls | More betting options and higher payouts than other variants | More complex and confusing than other casino games |
Online roulette is an enjoyable and thrilling game with various versions to match different likes and preferences. Each type of roulette variations comes with its pros and cons, and the ideal choice for you relies on your objectives, budget, and expertise. Experiment with different roulette games either best online roulette sites or at physical casinos to discover your favorite.
One distinctive feature of online roulette games is the availability of various betting options, including corner bets, outside bets, and inside bets. Players can tailor their playing style by choosing different variants and experimenting with strategic moves that suit their preferences. The option for demo play further enhances the experience, allowing both new and existing players to refine their skills without risking real money.
For those who appreciate the allure of a land-based casino, online platforms often collaborate with renowned software developers like Pragmatic Play to recreate the excitement in the virtual realm. These partnerships not only maintain the authenticity of the game but also introduce different variants with generous bonuses, enticing both new and existing players to explore the vast landscape of online roulette.
In the realm of responsible gaming, online platforms prioritize player well-being by promoting responsible betting practices. Through features like MGM Rewards and a lower house edge, players are encouraged to bet responsibly while enjoying the thrill of roulette. Embracing different variants, both new and experienced players can find a playing style that suits their preferences, creating a dynamic and engaging online roulette experience.
Is There Any Free Online Roulette Game?
Can I play online roulette free? There are Top 10 online roulette casino for real money that offer free online roulette games without requiring any sign-up or download. You can play different types of roulette, such as European, American, French, or Double Ball, and practice your skills or have fun. Some ball wheel casino websites offer free online roulette games on their home pages. However, roulette free playing has some drawbacks as well.
Advantages and shortcomings of playing free roulette games
| Main Pros 😊 | Main Cons 🙁 |
| 👍 Availability of roulette for real money games, and you can win big. You’re able to take away your winning amount any time you want! | 👎 You can’t earn real money or take out winnings by playing online roulette for free. It’s good for practice but doesn’t have the excitement of betting with real money. |
| 👍 Different roulette games. Live dealer roulette games. Various ways to improve your chances. | 👎 Free roulette games might not let you play the best roulette options or live dealer games. Some casinos might not allow free games or need to sign up for real money casinos. |
| 👍 Rewards and special deals to increase your money saved while playing longer. Rewards programs that give points, money back and free spins. | 👎 If you don’t sign up, you won’t get casino rewards or special deals. These can help your money grow, improve chances of winning and give you rewards for staying loyal. You need money playing online roulette professionally. |
| 👍 Playing in a safe, controlled place that is checked by outside organizations. Use trustworthy customer service and reliable gambling tools available at online casinos. | 👎 Be careful – roulette free sites without good licenses or safety features could show private and money details to bad people like hackers or scammers. Play roulette online in a lower risk environment. |
So, for people who want to play online roulette seriously, it’s a good idea to sign up with a trusted online casino roulette website that offers real money games. Searching the Internet can help you find some best roulette sites. Take time to read reviews, check features and choose the platform that matches your likes and money budget. Playing online roulette for real money has more benefits than trying this game for free.
Main Features of Casino Games with Ball Wheel
Choosing a roulette casino site can be a challenging task, as there are many factors to consider. Most online casinos offer different features and benefits for roulette players, such as minimum deposit, wagering rules, free spins, welcome deposit bonus, RTP%, payment methods, and cash withdrawal methods. These features may vary depending on the online casino and the roulette variant you choose. Therefore, you should always check the specific terms and conditions before playing for real money.
| Feature | Description |
| Minimum deposit | The initial deposit required to engage in online casino roulette games typically ranges from $5 to $20 or more, contingent on the specific casino and chosen payment method. |
| Wagering requirements | Before withdrawing your winnings, it’s essential to consider the wagering requirements, varying from 20x to 60x or more, depending on the casino and bonus type. |
| Free spins | New gamblers often enjoy a set number of complimentary spins on selected slots as part of welcome bonuses or promotions, with quantities ranging from 10 to 200 or more, depending on the casino offer. |
| Welcome bonus | Upon making your first online deposit, you may receive a deposit bonus of varying percentages, such as 100% to 500% or more, depending on the casino and the promotion. |
| RTP% | The return to player percentage, indicating the expected long-term winnings from your outside bets, ranges from 94% to 98% or more, contingent on the roulette variant and bet type. |
| Payment method | Diverse options for deposits and withdrawals at roulette casino sites include credit/debit cards, e-wallets, cryptocurrencies, prepaid vouchers, bank transfers, and more. |
| Cash withdrawal method | Selecting the withdrawal method may be the same or different from your deposit choice, with identity verification and meeting minimum withdrawal amounts often prerequisites for cashing out your earnings. |
| Famous software providers of live dealer roulette games | Evolution Gaming |
| Licenses | Malta Gaming Authority; United Kingdom Gambling Commission; Curacao eGaming |
The best online casinos also offer other roulette table games, such as blackjack, baccarat, poker, and more. You can play these games for free or real money, depending on your preference and skill level. You can also take advantage of the roulette site bonuses, which can boost your bankroll and increase your chances of winning. However, you should also be aware of the wagering requirements and other restrictions that may apply.
To find the top online casinos for roulette, you can use some of the web search results that I found for you. These best roulette sites can help you compare and review different sites, based on their features, reputation, customer service, and more. You can also read the feedback and ratings from other roulette players, who can share their experiences and opinions. By doing your own research and comparison, you can find the best gambling sites for your needs and preferences.
What is the Online Roulette Winning Strategy?
How to play online roulette for real money successfully? When devising a successful roulette online winning strategy, consider the dynamic option of betting on two numbers. This approach allows players to diversify their bets beyond the standard single-number choices. By selecting specific numbers or opting for odd or even combinations, players introduce an element of strategy that goes beyond the simplicity of traditional wagers.

A strategic move involves betting on adjacent numbers, leveraging the correlation between them for potentially enhanced outcomes. Industry standards often highlight the importance of understanding the full terms associated with each bet, ensuring that players make informed decisions that align with their risk tolerance and desired outcomes.
For a nuanced strategy, incorporating the concept of a “chase losses” approach can be beneficial. While it’s essential to bet on two numbers with one unit, the strategy involves adjusting subsequent bets to recover losses gradually. Fellow players often appreciate the real difference this strategy can make, creating a sense of camaraderie as everyone explores diverse approaches to the game.
Top tips for maximizing the online roulette experience include utilizing live chat features, particularly for players residing in different locations. Engaging with fellow players in real-time not only adds a social element but also provides valuable insights into various winning strategies. It transforms the game into a fun experience where players can exchange ideas and learn from each other’s successes and challenges.
What Payment Method to Use in Ball Wheel Casino Games on Reputable Sites?



Picking the best payment method for casino games with balls can be different for everyone. Each type of payment has good and not-so-good points, depending on what you like or don’t like. But the safety is important. Try to choose only online roulette legal platforms, as various factors warrant consideration:
- Security: Check if your personal and money details are safe. Believing in both the payer service and the casino’s ability to keep your information safe is very important. Check what options are there if you have any problems.
- Speed: Check how fast deposits and withdrawals are processed. Check if there are long waits and see if fast transactions cost extra money.
- Convenience: Think about how simple it is to use a payment method. Check if you need to make an account or prove your identity. Check how much detail or proof is needed and find out if you have to change between tools or gadgets.
- Availability: Look at how widely accepted a payment method is among online casino games. Check if certain gambling places allow your chosen way of paying and see if there are any rules about being in a specific place or using different types money.
Taking these things into account, some payment options might match your likes more. For example, if being safe and secret are very important then using things like Bitcoin or Paysafecard could be better choices. Instead, if you want speed and ease then using PayPal or Neteller would be better. For people who care about having something ready to use and dependable, normal methods like Visa or Mastercard might be their favorite pick.
Final Thoughts to Sum Up Playing an Roulette Game Online
In conclusion, roulette is a popular and exciting game that has many variations and features. You can play roulette for fun or visit an online roulette real money casino and enjoy the thrill of spinning the wheel and winning big as you already know the top 10 online roulette casino sites for real money which our team gladly presented you. Discover the truth about online roulette and dispel myths surrounding ‘online roulette rigged’ claims through transparent and reputable platforms!
When it comes to roulette, making a deposit at reputable sites is essential. Our top picks ensure a secure and seamless deposit process, allowing you to dive into the world of individual numbers and explore a wide selection of betting options with confidence. Worth checking for a hassle-free gaming experience.
Frequently Asked Questions (FAQs) about Online Roulette Sites
- What is American Roulette, and how can I play it online?
- American Roulette is a popular casino game. You can play it on various online gaming sites. Check out our recommended online casinos for the real casino experience.
- What’s the significance of a live dealer in online roulette?
- A live dealer enhances the gaming experience by providing real-time interaction. PokerStars Casino is known for its excellent live dealer games, including American and roulette European game.
- What is the PokerStars Casino site?
- PokerStars Casino is a renowned casino site offering a diverse game selection, including popular casino games like American Roulette. It’s known for its extensive game library and top-notch gaming experience.
- Are there any specific rules for playing roulette online?
- Yes, understanding roulette rules is crucial. Familiarize yourself with the game’s basics, such as split bets, corner bets, and even-money bets, to enhance your gameplay.
- Can you recommend online casinos where I can play American Roulette and other popular games?
- Explore our list of recommended online casinos for a diverse range of games, including American Roulette variants, slot games, and jackpot games.
- How can I avoid losing money while playing roulette online?
- Employing effective roulette strategies can help minimize losses. Learn about different strategies and play responsibly to enhance your chances of winning.
- What are the space invaders roulette and double ball roulette?
- Space Invaders Roulette and Roulette with two balls are exciting variants. Some top online casinos, such as Wild Casino, offer these innovative games for a unique gambling experience.
- Is mobile roulette a popular option for casino players?
- Yes, mobile roulette allows online roulette players to enjoy their best roulette games on the go. Many outstanding casinos offer a mobile version compatible with your computer or mobile device.
- What are the advantages of playing at real money online casinos?
- Real money online casinos offer the thrill of wagering real money, providing opportunities to win cash prizes. Check out our top casino sites for an authentic gambling experience.
- What are the features od the American Roulette table?
- The American Roulette table is a classic roulette game with a spinning wheel and split bet strategy. Learn about the odds of winning and different types of bets, such as outside bets and split bets.
- Which online casinos offer deposit match bonuses?
- Many top casinos provide deposit match bonuses as part of their welcome 150% bonus package. Check the qualifying deposit and terms to maximize your bonus money.
- What is Lightning Roulette, and where can I play it online?
- Lightning Roulette is a version of the game with exciting features. Some top casino sites, like Cafe Casino, offer this thrilling variant for an enhanced gaming experience.
- How can I play responsibly when enjoying online roulette?
- Responsible gambling is essential. Set limits, play within your means, and be aware of the potential risks. Enjoy the game without jeopardizing your financial well-being.
- Do online casinos cater to Canadian players?
- Yes, many online casinos welcome Canadian players. Explore our recommended casinos for an enjoyable gaming experience with various payment options and casino credits.
- What are the basic rules of roulette, and how do I improve my odds of winning?
- Understanding basic rules, such as those related to even-money bets, is crucial. Explore different strategies to enhance your odds of winning in this classic game.
- Can you explain the concept of a welcome bonus package at online casinos?
- A welcome bonus package typically includes bonus money and may involve free play or additional perks. Check the terms and conditions for details on how to claim these bonuses.
- What is the role of a dealer in online roulette games available?
- In live dealer games, a real dealer facilitates the game. Enjoy the authentic casino experience with dealer games, enhancing the excitement of playing roulette online.
- What is Zoom Roulette, and where can I find it online?
- Zoom Roulette is a unique version of the game. Some top casinos, offering extensive game libraries, feature this variant for an exciting and fast-paced gaming experience.
- What are outside bets, and how do they work in roulette?
- Outside bets in roulette involve wagering on broader outcomes, providing different odds. Familiarize yourself with these bets for a more comprehensive understanding of the game.
- What banking options are available for depositing and withdrawing at online casinos?
- Top casino sites offer a variety of banking options, allowing you to deposit and withdraw funds securely. Explore the payment options available to find the most convenient method for you.
- What are the popular slot titles offered by the best online roulette casinos, and do they include any exclusive slots tournaments for players?
- In addition to the European roulette options, leading online casinos often feature a diverse selection of popular slot titles. Some even organize exciting slots tournaments, providing players with a chance to win money while enjoying their favorite games.
- Are there more roulette variations available online compared to brick and mortar casinos, and do these top online platforms use a reliable random number generator for fair play? Best online roulette platforms typically offer a broader range of roulette different variations than traditional brick and mortar casinos. Additionally, these platforms prioritize fairness by employing advanced random number generators, ensuring every spin is genuinely random and providing an authentic Las Vegas experience.
- Can players find even-money bet options in the online version of top roulette casinos, and do they offer excellent customer service for assistance?
- Can players find even-money bet options in the online version of top roulette casinos, and do they offer excellent customer service for assistance? Even-money bet options, a hallmark of classic roulette, are commonly available in the online versions of top roulette casinos. Furthermore, players can expect excellent customer service, receiving prompt assistance and support whenever needed.
- What distinguishes auto roulette from other roulette variations, and are there zero roulette options available in the top online roulette casinos? Auto roulette is a popular feature in the most outstanding roulette casino sites, allowing players to enjoy automated gameplay for added convenience. Additionally, these platforms often offer zero roulette options, enhancing the variety of gameplay and strategies available to players.
- Which software developers contribute to the best online roulette casinos, and what line bet options do they offer to players seeking a customized gaming experience? Best online roulette casinos collaborate with renowned software developers to provide a seamless and enjoyable gaming experience. Players can explore various line bet options, tailoring their bets to suit their preferences and increasing their chances to win money in the diverse world of online roulette.
- Are there any dedicated mobile apps to play roulette online? Yes, if the casino provides its version for mobile devices, you can download software from AppStore, Google Play for android and ios devices, or the casino’s website and enjoy the game.
Explore the thrill of betting on individual numbers in roulette games at our recommended sites, where a wide selection of options awaits you for a truly personalized gaming experience. These sites are worth checking out for enthusiasts seeking the excitement of predicting the winning number with precision.
*Sed hendrerit libero eros, ut faucibus ante pulvinar in. Integer erat sem, aliquam at eros sed, gravida lobortis elit. Suspendisse metus sem, dignissim et eleifend a, malesuada vel tortor. Nulla sit amet velit quis tellus convallis facilisis a et mi. Donec luctus, arcu in accumsan auctor, ligula ante dictum lectus, lobortis pellentesque tellus magna quis felis.
![Random Number Generator [1 to 6]](https://roulette-roulette.net/wp-content/uploads/2023/12/PHOTO-2023-12-20-18-40-14-2-450x338.jpg)




Try Fire Joker slot online for free in demo mode with no download and no registration required and read the game's review before playing for real money.

100% match bonus based on first deposit of £/$/€20+. Additional bonuses.

100% match bonus based on first deposit of £/$/€20+. Additional bonuses.

100% match bonus based on first deposit of £/$/€20+. Additional bonuses.
![Random Number Generator [1 to 6]](https://roulette-roulette.net/wp-content/uploads/2023/12/PHOTO-2023-12-20-18-40-14-2-737x407.jpg)
![Random Number Generator [1 to 6]](https://roulette-roulette.net/wp-content/uploads/2023/12/PHOTO-2023-12-20-18-40-14-2-450x407.jpg)




100% match bonus based on first deposit of £/$/€20+. Additional bonuses.
100% match bonus based on first deposit of £/$/€20+. Additional bonuses.
100% match bonus based on first deposit of £/$/€20+. Additional bonuses.
100% match bonus based on first deposit of £/$/€20+. Additional bonuses.








*Donec scelerisque fermentum sem, vel feugiat massa egestas tristique. Ut semper vulputate est. Proin sodales libero ac egestas lobortis. Fusce nec lectus vitae ex ultricies egestas. Mauris vitae vulputate tortor. Fusce malesuada auctor quam, eu cursus urna placerat in. Aliquam sit amet dignissim tellus, non porta massa. Fusce rhoncus ornare dui in facilisis.
![Random Number Generator [1 to 6]](https://roulette-roulette.net/wp-content/uploads/2023/12/PHOTO-2023-12-20-18-40-14-2-570x407.jpg)
-
JokaBet Reviews
1 week ago 0 16
-
No Deposit bonus offers
2 months ago 0 80
-
Roulette Table Payout
2 months ago 0 150
-
What are Roulette Payouts?
3 months ago 0 88
-
Free Online Roulette Simulator
3 months ago 0 169







Make your first deposit of at least $10, and the online casino will match it up to $1,000. ... It's a low- to medium-variance slot with a maximum win of 1,000 ...
It's not unusual for online casino operators to hand out crazy bonuses. Some of these even go as high as 1,000 free spins with no deposit!






